When using TiDB, you may occasionally encounter some exceptions, such as the “Lost connection to MySQL server during query” error. This indicates that the connection between the client and the database has been disconnected (not due to user action). The reasons for disconnection can vary. This article attempts to analyze some common TiDB errors from the perspective of exception handling and code analysis. Additionally, some exceptions are not errors but performance issues due to slow execution. In the second half of this article, we will also introduce common tools for tracking performance.
Lost Connection
There are generally three reasons for a Lost Connection:
- A timeout occurs either directly between the client and the database or at some point along the intermediate link, such as from the client to the Proxy or from the Proxy to the database.
- A bug occurs during SQL execution, which can generally be recovered, thus preventing the TiDB server from crashing completely (panic).
- TiDB itself crashes, often due to excessive memory use, causing an OOM (Out of Memory), or a user deliberately kills TiDB. Another possibility is an unrecovered bug, which typically appears more frequently in background threads.
Timeout
Direct Timeout
TiDB supports the MySQL-compatible wait_timeout variable, with a default value of 0, meaning no timeout is set, unlike MySQL’s default of 8 hours.
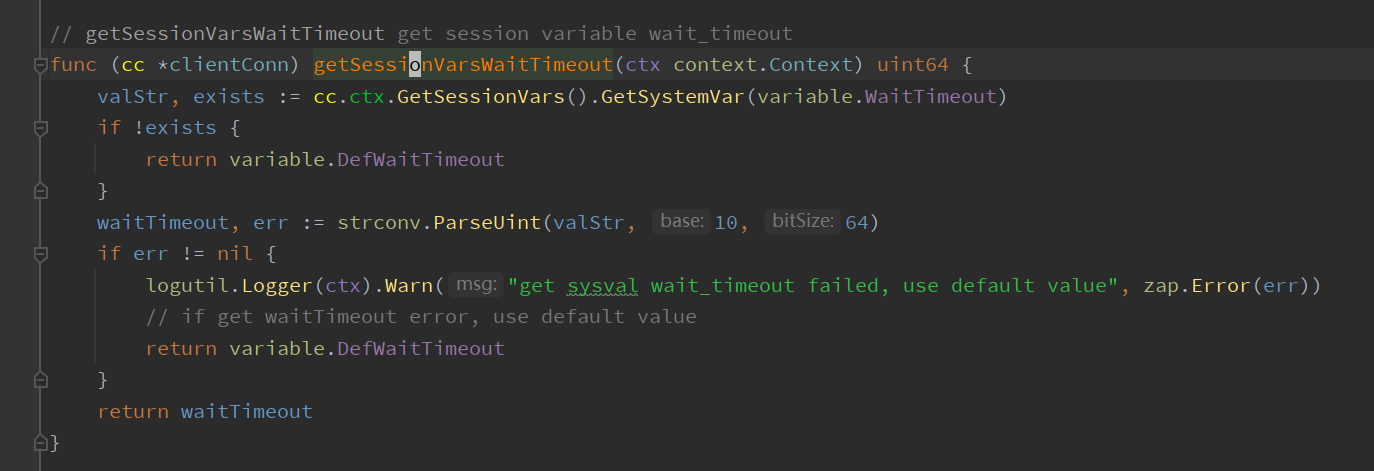
The only place it is used in the code is in getSessionVarsWaitTimeout. In the connection’s Run section, its value is set for packet IO. If the variable is non-zero, a timeout is set before each readPacket.
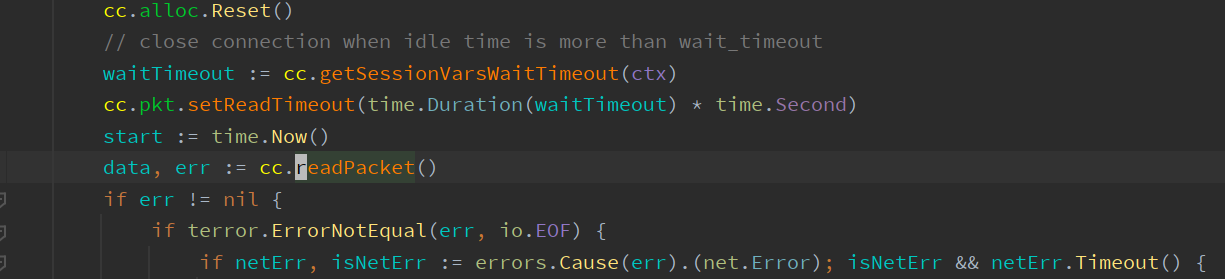
If the client does not send data beyond the specified time, the connection will be disconnected. At this time, a log message “read packet timeout, close this connection” will appear, along with the specific timeout duration.
Intermediate Link Timeout
Another scenario is an intermediate link timeout. A normal timeout in an intermediate link (proxy) typically returns an EOF error to the database. In older versions, at least a connection closed log would be output.

In the newer master version, product managers suggested changing this log to a debug level, so it is generally no longer output.
However, in the new version, a monitoring item called DisconnectionCounter has been added,
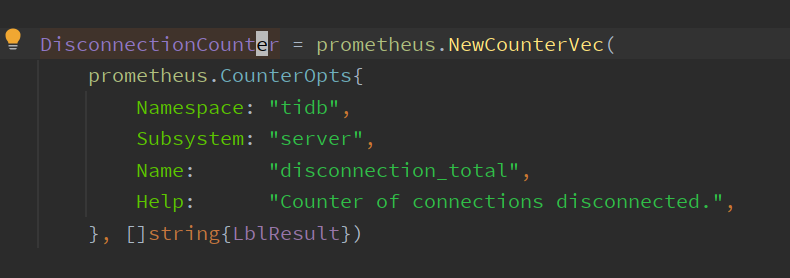
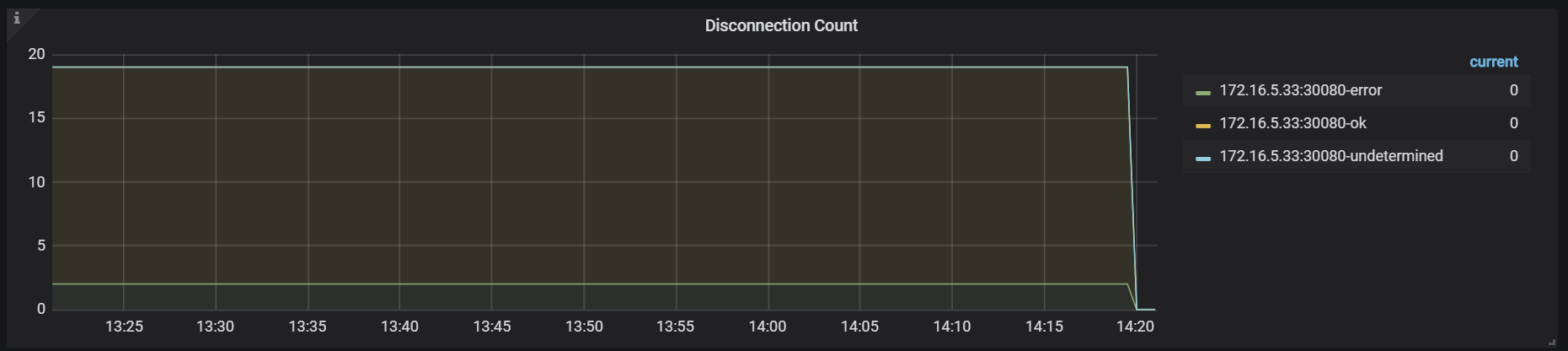
which records normal and abnormal disconnections as a supplement to downgraded logging.
Bugs that Are Recovered
TiDB “basically” can recover from panics caused by unknown bugs. However, if there is an array out-of-bounds, a null pointer reference, or intentional panic, it cannot guarantee correct results for the current and subsequent SQL, so terminating the current connection is a wise choice.
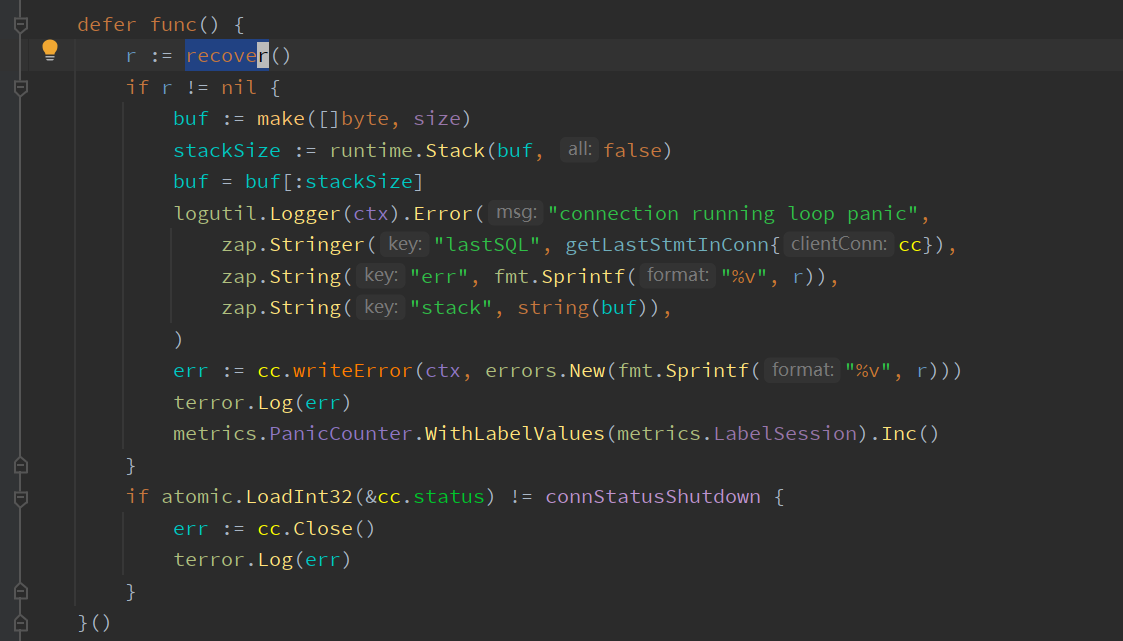
At this time, an error log “connection running loop panic” will appear, along with a lastSQL field that outputs the current erroneous SQL.
Panic Not Recovered
Whether it’s an unrecovered panic or a system-level OOM-induced panic, they do not leave a log in TiDB’s logs. TiDB clusters managed by deployment tools like Ansible or TiUP will automatically restart a crashed TiDB server. Consequently, the log will contain a new “Welcome” message, which might be overlooked. However, the Uptime in monitoring will show TiDB’s Uptime reset to zero, making this issue relatively easy to detect. Of course, it’s better to have accompanying alerts.
Unrecovered panic outputs are Golang’s default outputs, usually redirected to tidb_stderr.log by deployment tools. Older versions of Ansible overwrite this file every restart, but now use an append mode.
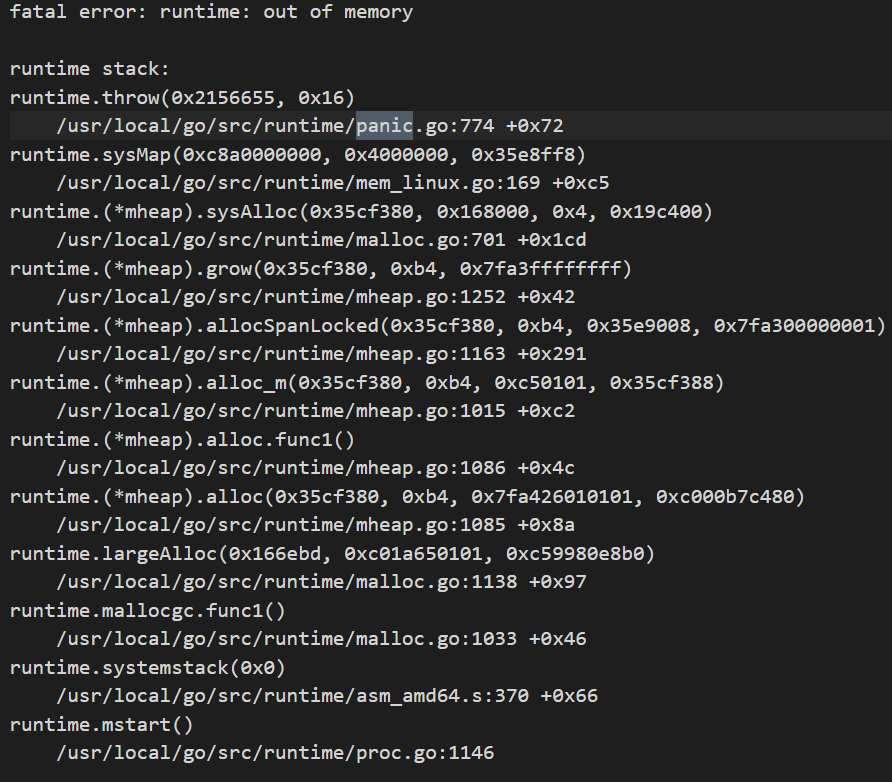
Nevertheless, it has some other drawbacks, like lacking timestamps. This makes it difficult to timestamp-match with TiDB logs. This PR implemented distinguishing tidb_stderr.log based on PID but hasn’t been coordinated with the deployment tools and is temporarily disabled.
To get this standard panic output, you can use the panicparse introduced in the previous article to parse the panic results. Typically, you can look at the topmost stack. The example in the image evidently shows an out-of-memory error, commonly referred to as OOM. To identify which SQL caused the OOM, check TiDB’s logs for resource-heavy SQL, which are usually logged with the expensive_query tag, and can be checked by grepping the logs. This will not be exemplified here.
Tracing
TiDB has supported tracing since version 2.1, but it hasn’t been widely used. I think there are two main reasons:
The initial version of tracing only supported the JSON format, requiring the output to be copied and pasted into a TiDB-specific web page at a special host port to view it. Although novel, the multiple steps involved prevented widespread adoption.
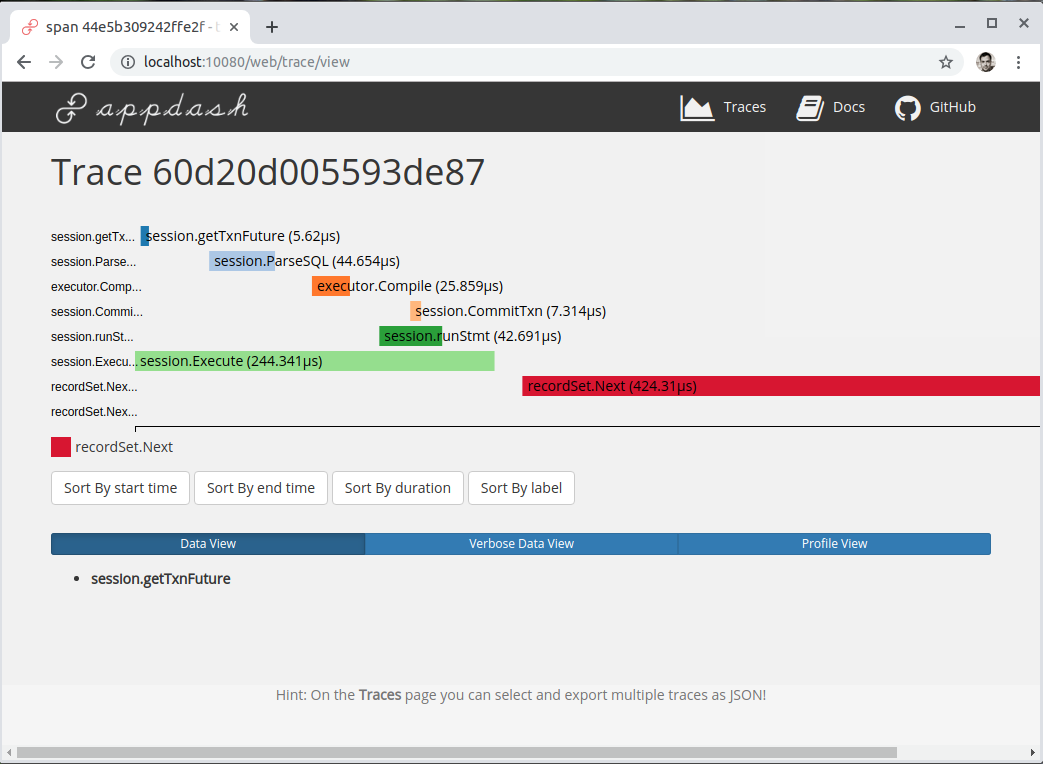
Another issue is that tracing provides insight only after a problem is known. If developers suspect a problem or slow execution in advance, they must proactively add events at those points. Often, unforeseen issues cannot be covered, leaving gaps.
Once the framework of tracing is in place, adding events is relatively straightforward and involves adding code like the snippet below at the desired points:

Interested individuals can add events to TiDB as needed, offering a good hands-on experience.
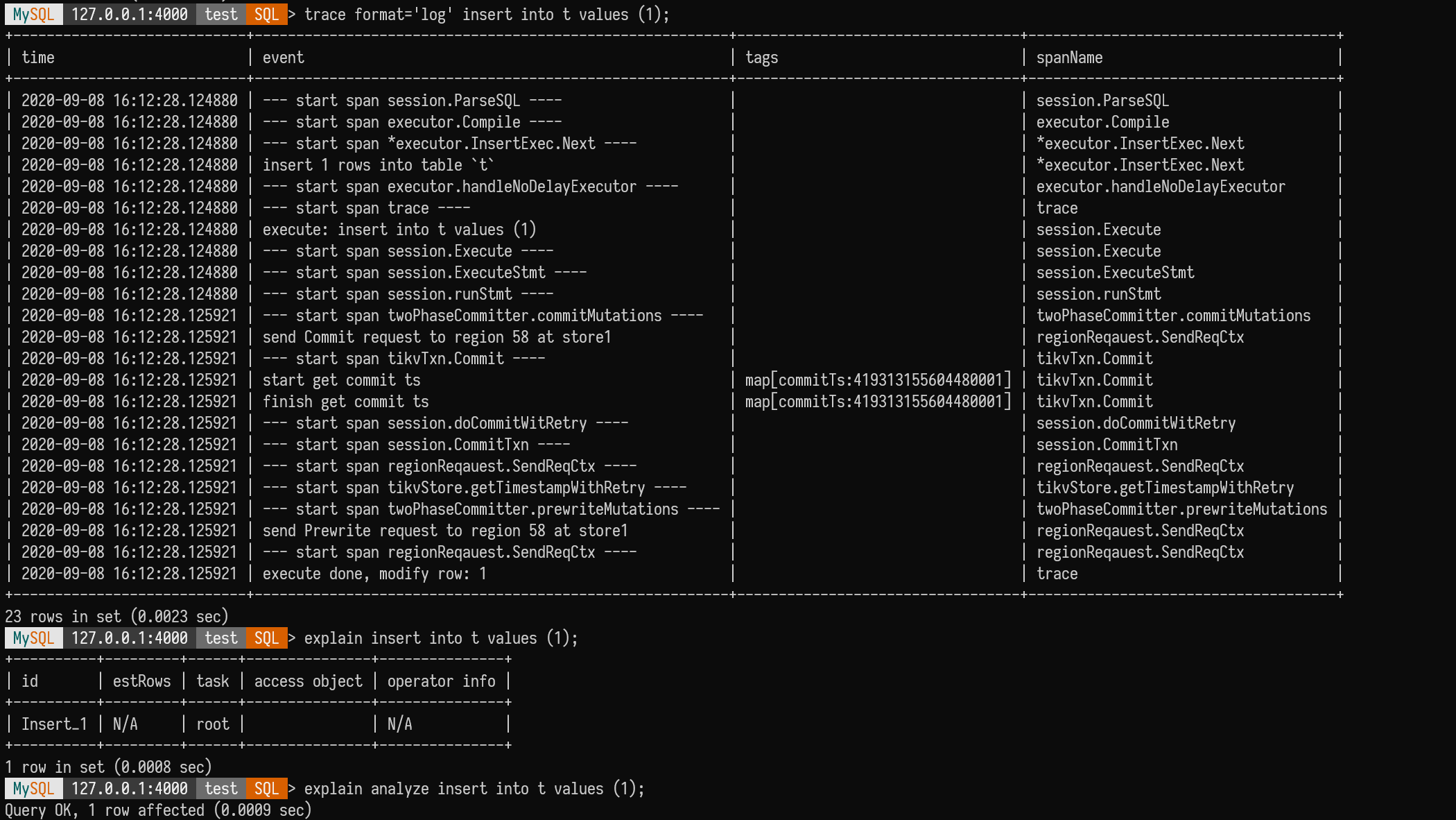
Eventually, tracing added format='row' and format='log' features,
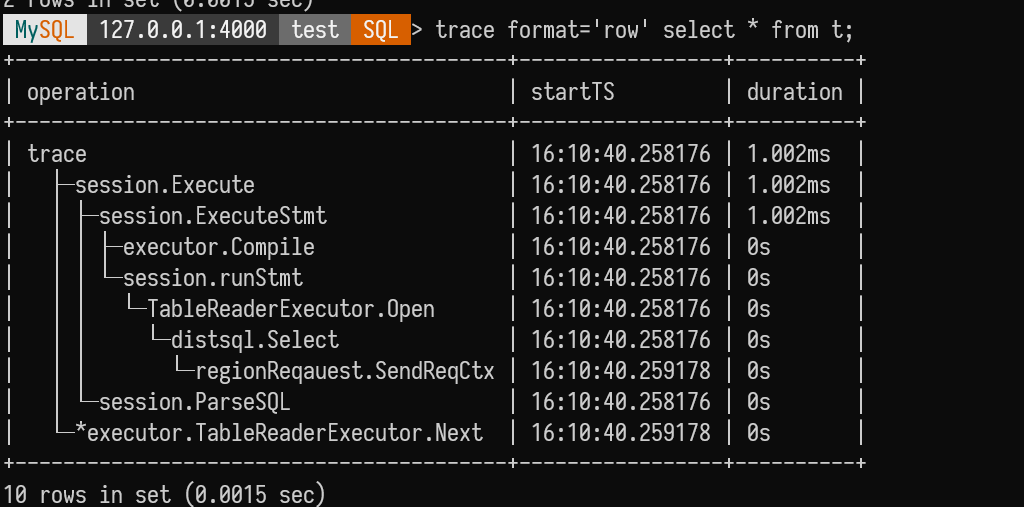
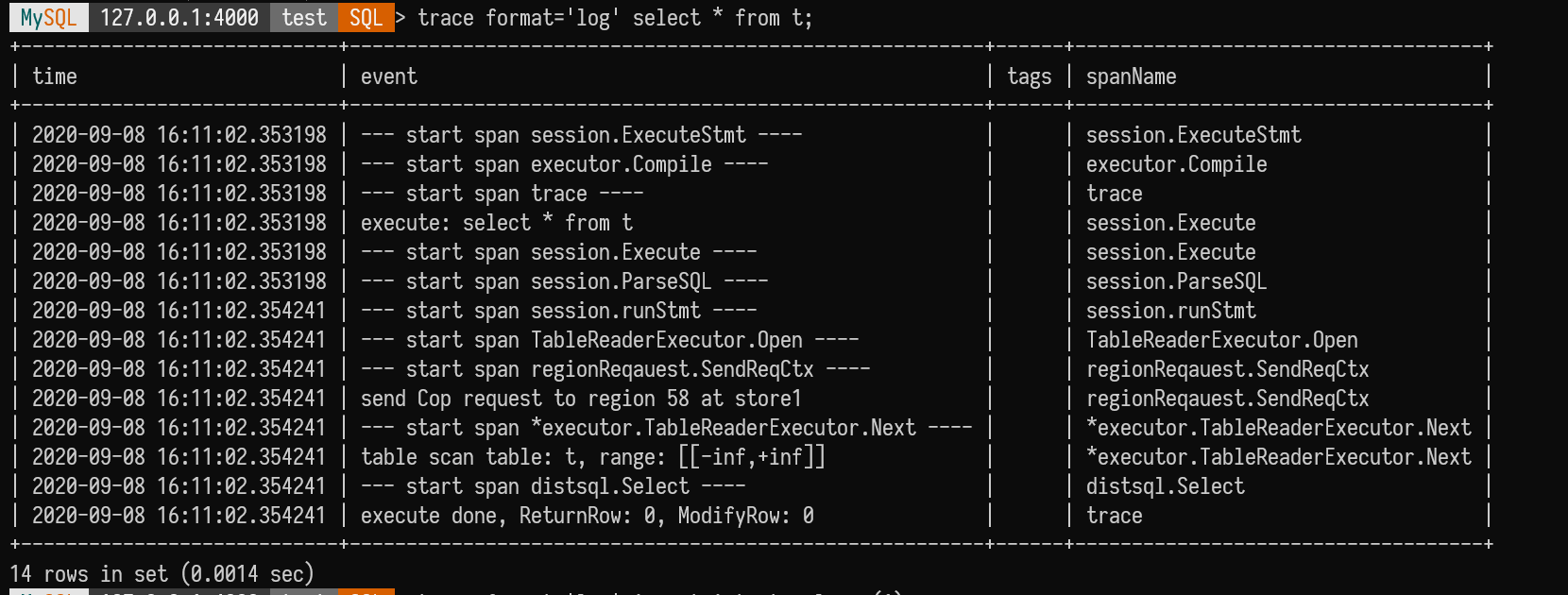
I personally favor format='log'.
Difference between Tracing and Explain (Analyze)
- Tracing operates at the function level, while Explain operates at the operator level. Tracing is easier to add and more granular and does not need to be part of a plan.
- Tracing can trace any SQL, while Explain only shows data reading parts. For example, with an Insert, Explain shows almost nothing, whereas tracing provides detailed insights from SQL parsing to the full transaction commit.